
애플리케이션 아키텍쳐
계층형 구조
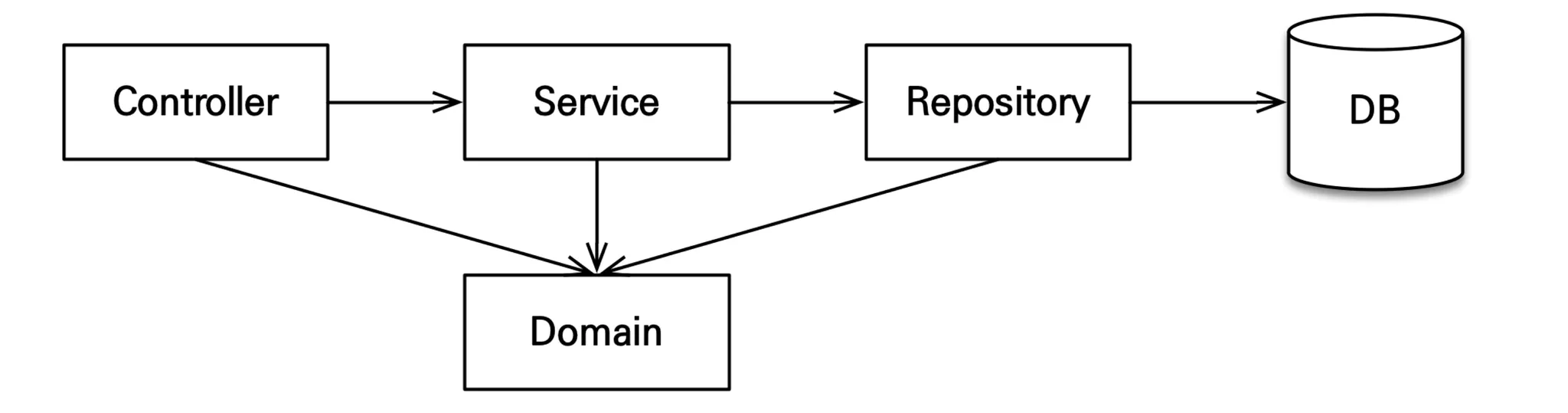
- controller : 웹 계층
- service : 비즈니스 로직, 트랜잭션 처리
- repository : JPA를 직접 사용하는 계층, 엔티티 매니저 사용
- domain : 엔티티가 모여 있는 계층, 모든 계층에서 사용
회원 서비스 개발
@Service
@Transactional(readOnly = true)
@RequiredArgsConstructor
public class MemberService {
private final MemberRepository memberRepository;
@Transactional
public Long join(Member member) {
validateDuplicateMember(member);
memberRepository.save(member);
return member.getId();
}
private void validateDuplicateMember(Member member) {
List<Member> findMembers = memberRepository.findByName(member.getName());
if (!findMembers.isEmpty()) {
throw new IllegalStateException("이미 존재하는 회원입니다.");
}
}
}
@Transactional(readOnly=true) 는 데이터의 변경이 없는 읽기 전용 메서드에 사용하는 어노테이션이다. 영속성 컨텍스트를 flush하지 않으므로 성능적인 면에서 약간의 이점이 존재한다.
필드 주입
@Service
@Transactional(readOnly = true)
public class MemberService {
@Autowired
private MemberRepository memberRepository;
}
현재 코드는 필드 주입(Field Injection) 방식을 사용하고 있다. 필드 주입은 멤버 객체에 @Autowired를 붙여 주입받는 방법이다. 즉, 주입 받고자 하는 필드 위에@Autowired 어노테이션을 붙여주기만 하면 스프링이 직접 의존성을 주입해준다. 하지만 이런 필드 주입은 여러 단점이 존재한다.
먼저 Field Injection을 사용하면 final 제어자를 사용하지 못한다. 즉, 중간에 MemberRepository 객체가 변경될 수도 있다는 뜻이다. 이는 런타임 중에 repository의 불변성을 보장 받을 수 없게 만든다. 또한 테스트 코드를 짜는 데에 있어서도 불편함이 있다. 필드 주입은 달랑 필드 위에 @Autowired 애노테이션이 달려있는 구조이기 때문에 스프링의 도움을 받지 않으면 객체를 생성하기 어렵다. 따라서 테스트를 하려면 프로젝트 전체를 돌려야 한다. 이는 무거운 프레임워크를 피해 자바 코드만으로 가동하려는 테스트의 의미를 무색하게 만든다.
생성자 주입
필드 주입 방식을 생성자 주입 방식으로 바꿔보자.
@Service
@Transactional(readOnly = true)
public class MemberService {
private final MemberRepository memberRepository;
@Autowired // 생성자가 하나면 해당 어노테이션을 생략할 수 있다.
public MemberService(MemberRepository memberRepository) {
this.memberRepository = memberRepository
}
}
생성자 주입은 생성자에 @Autowired을 붙여 의존성을 주입하는 방법으로 객체의 최초 생성 시점에 스프링이 의존성을 주입해준다. Spring Framework에서 공식적으로 권장하고 있는 방식으로 생성자가 1개 밖에 존재하지 않을 경우 @Autowired를 생략할 수 있다. 생성자 주입 방식을 사용하게 되면 필드에 final 키워드를 사용할 수 있고 의존성 주입이 최초 1회만 이루어져 객체의 불변성을 확보할 수 있다. 특히, final 키워드를 추가하면 컴파일 시점에 memberRepository를 설정하지 않은 오류를 체크할 수 있다는 이점이 있다.
위의 코드에서 lombok에서 제공하는 @RequiredArgsConstructor 어노테이션을 사용하면 아래와 같이 코드를 줄일 수 있다.
@Service
@Transactional(readOnly = true)
@RequiredArgsConstructor
public class MemberService {
private final MemberRepository memberRepository;
}
회원 기능 테스트
영속화(persist)와 쿼리문
@Test
public void 회원가입() throws Exception {
// given
Member member = new Member();
member.setName("kim");
// when
Long saveId = memberService.join(member);
// then
assertEquals(member, memberRepository.findOne(saveId));
}
위는 회원가입 로직을 검증하기 위한 테스트 코드이다. 이때 이 함수를 실행시키면 쿼리문이 어떻게 나갈까?

회원이 추가되었기 때문에 insert문 쿼리가 나갈 것이라는 우리의 예상과는 다르게 insert문 쿼리 없이 select문 쿼리만이 실행된 것을 확인할 수 있다. 그 이유가 무엇일까? 이를 알기 위해서는 영속성 컨텍스트의 동작 과정에 대해서 선제적으로 알아야 한다. 지금부터 살펴보자
먼저 join 메소드의 코드를 살펴보자.
// MemberService
@Transactional
public Long join(Member member) {
validateDuplicateMember(member);
memberRepository.save(member);
return member.getId();
}
// MemberRepository
public void save(Member member) {
em.persist(member);
}
우리는 새로운 Member 객체를 저장하기 위해 엔티티매니저에 persist() 메서드를 통해 영속화하고 있다. 여기서 중요한 점은 단순히 ‘영속화’를 한다는 점이다. 즉, DB에 반영되는 것이 아니다! persist 메소드를 통해 객체를 영속화하면 1차 캐시에 저장되는 동시에 쓰기 지연 SQL 저장소에도 SQL 쿼리문이 생성되어 저장된다. persist를 할 때마다 쓰기 지연 SQL 저장소에는 생성된 SQL 쿼리문이 차곡차곡 쌓이게 되고 그 후 트랜잭션이 커밋되면 비로소 DB에 반영 즉, insert문 쿼리가 나가게 되는 것이다.
하지만 테스트 클래스에서 적용되는 @Transactional 은 트랜잭션이 commit 되지 않고 rollback되게 된다. 때문에 쓰기 지연 SQL 저장소에 쌓인 insert 쿼리문이 실행되지 않는 것이다.
Junit5
강의에서는 테스트코드를 Junit4를 이용해서 아래와 같이 작성하고 있다.
@Test(expected = IllegalStateException.class)
public void 중복_회원_예외() throws Exception {
// given
Member member1 = new Member();
member1.setName("kim");
Member member2 = new Member();
member2.setName("kim");
// when
memberService.join(member1);
memberService.join(member2);
// then
fail("예외가 발생해야 한다!")
}
내가 사용하는 Junit 버전은 5였기 때문에 위의 코드를 따라치자 Cannot resolve method ‘expected’ 라는 오류가 발생했다. 찾아보니 Junit 5에서는 expected 속성을 지원하지 않아 발생되는 오류였으며 대신에 Junit5에서는 assertThrows 메서드를 사용하여 예외가 발생하는지 확인할 수 있다고 한다.
아래 코드는 강의에서의 코드를 assertThrows 메서드를 활용하여 재작성한 코드이다.
@Test
public void 중복_회원_예외() throws Exception {
// given
Member member1 = new Member();
member1.setName("kim");
Member member2 = new Member();
member2.setName("kim");
// when & then
assertThrows(IllegalStateException.class, () -> {
memberService.join(member1);
memberService.join(member2);
});
}
참고로 처음에 테스트코드에 사용한 함수들에 대한 명확한 이해없이 assertThrows 함수 아래에 fail("예외가 발생해야 한다!") 을 작성하니 테스트가 실패하는 오류가 발생하였다. 그 이유가 궁금하다면 아래 링크를 참고해보자.
https://dkswnkk.tistory.com/441
https://www.inflearn.com/community/questions/253006/junit5-의-assertions-fail-에-대해-질문이-있습니다
테스트 케이스를 위한 설정
테스트는 케이스를 격리된 환경에서 실행하고 테스트가 끝나면 데이터를 초기화하는 것이 좋다. 그렇다면 테스트를 완전히 격리된 환경에서 할 수 있는 방법은 무엇일까? 바로 메모리 DB를 활용하는 것이다.

상품 도메인 개발
상품 엔티티 - 비즈니스 로직 추가
@Entity
@Getter
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name = "dtype")
public abstract class Item {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "item_id")
private Long id;
private String name;
private int price;
private int stockQuantity;
@ManyToMany(mappedBy = "items")
private List<Category> categories = new ArrayList<>();
public void addStock(int quantity) {
this.stockQuantity += quantity;
}
public void removeStock(int quantity) {
int restStock = this.stockQuantity - quantity;
if (restStock < 0) {
throw new NotEnoughStockException("need more stock");
}
this.stockQuantity = restStock;
}
}
응집력의 관점에서 볼 때, 데이터를 가지고 있는 쪽에 비즈니스 메소드가 있는 것이 좋다. 때문에 Item 엔티티에 stockQuantity를 활용하는 핵심 비즈니스 메소드를 엔티티에 직접 추가하였다.
Merge vs Persist
public void save(Item item) {
if (item.getId() == null) {
em.persist(item);
} else {
em.merge(item);
}
}
save함수를 동작 로직을 살펴보면, id가 없을 경우 persist()를 실행하고 있을 경우, 데이터베이스에 저장된 엔티티를 수정하는 merge()를 실행한다. 여기서 persist()와 merge()의 차이점이 무엇일까?
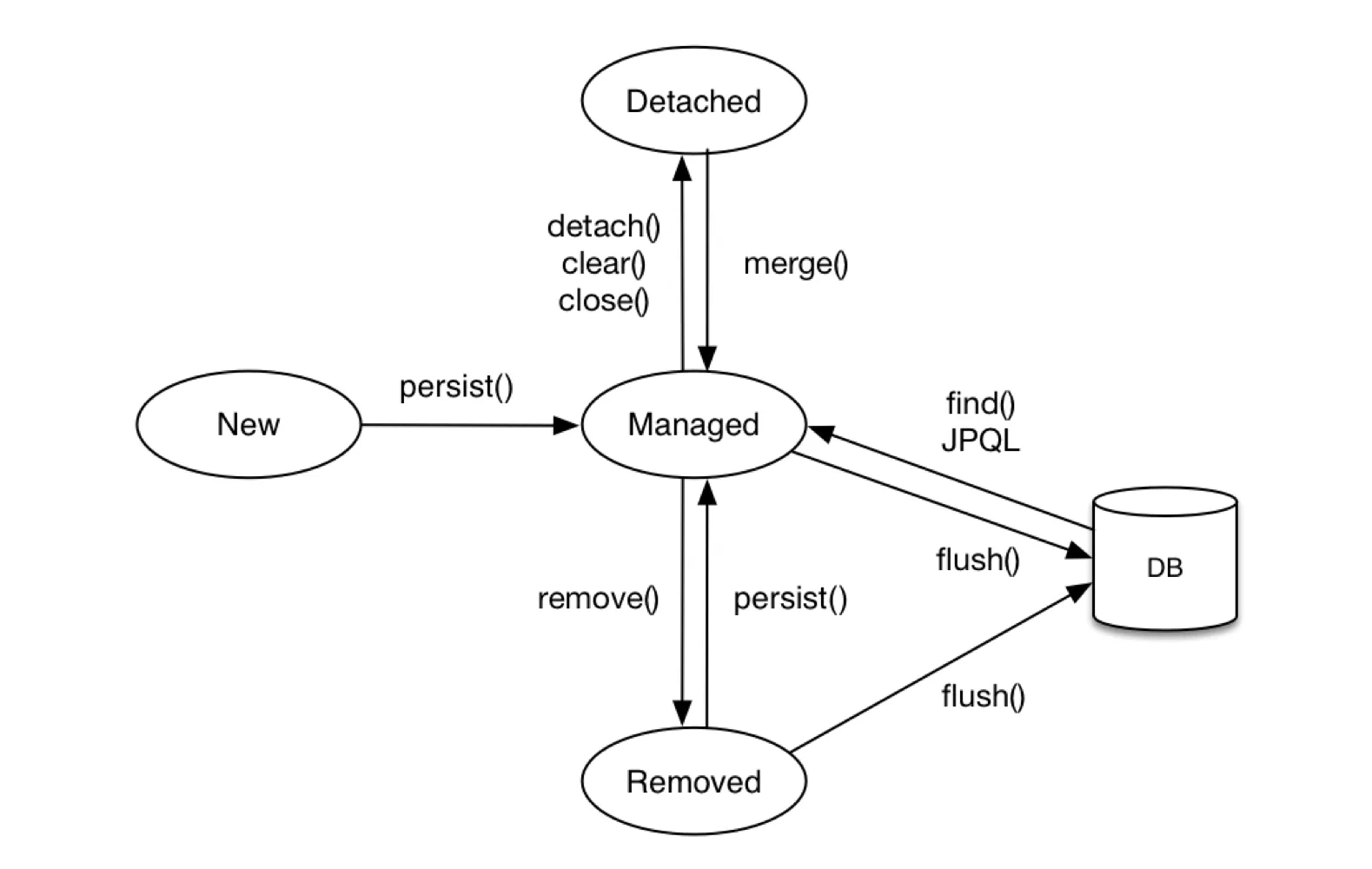
Merge는 Detached 상태의 Entity를 다시 영속화 하는데 사용되고 Persist는 최초 생성된 Entity를 영속화하는데 사용된다. 지금은 그냥 간단하게 persist는 비영속 상태를 영속 상태로, merge는 준영속 상태를 영속 상태로 바꿔준다고만 알아두자. → 더 자세한 내용은 섹션 7 웹 계층에서 다룬다.
주문 도메인 개발
가변인자
가변인자, 말 그대로 여러 개의 매개변수를 받을 수 있다는 뜻이다. 가변인자를 사용하면 메서드 호출 시에 전달되는 인자의 개수를 동적으로 변경할 수 있다. 배열을 포함한 모든 참조자료형(Wrapper Class, String, Object, List, Map)이 가변인자로 사용 가능하지만 기본 자료형은 가변인자로써 사용할 수 없다. 가변인자를 사용하는 방법은 간단하다. 아래 코드처럼 변수 타입 뒤에 기호(...)를 붙여주면 된다. 다만, 다른 파라미터와 가변인자를 같이 사용하는 경우에는 가변인자를 제일 뒤에 위치시켜야 한다.
public static Order createOrder(Member member, Delivery delivery, OrderItem... orderItems) {
Order order = new Order();
order.setMember(member);
order.setDelivery(delivery);
for (OrderItem orderItem : orderItems) {
order.addOrderItem(orderItem);
}
order.setStatus(OrderStatus.ORDER);
order.setOrderDate(LocalDateTime.now());
return order;
}
그렇다면 왜 가변인자를 사용하는 것일까? List 자료형을 활용해도 되지 않을까? 아래 코드를 살펴보자.
// 가변인자 사용
public void printArgs(String... args) {
for (String arg : args) {
System.out.println(arg);
}
}
// 리스트 사용
public void printArgs(List<String> args) {
for (String arg : args) {
System.out.println(arg);
}
}
// -------------------------------- 함수 호출 ----------------------------------- //
// 가변인수 사용 함수 호출
printArgs("Hello", "World");
// List 사용 함수 호출
List<String> args = Arrays.asList("Hello", "World");
printArgs(args);
두 메서드는 매개변수의 타입 외에는 차이가 없고, 기능적으로 동일하다. 다만 메서드를 호출함에 있어 가변인자는 호출 코드의 가독성과 사용편의성을 높일 수 있는 장점이 있음을 확인할 수 있다.
영속성 전이
영속성 전이는 특정 엔티티를 영속 상태로 만들 때 연관된 엔티티도 함께 영속 상태로 만들고 싶을 때 사용한다. 영속성 전이는 연관관계를 매핑하는 것과 아무런 관련이 없다. 단지 엔티티를 영속화할 때 연관된 엔티티도 함께 영속화하는 편리함만을 제공할 뿐이다. CASCADE는 두 엔티티의 생명주기기 일치하고 부모-자식 관계처럼 소유자가 단 한개 뿐일 때 사용하면 편리하다.
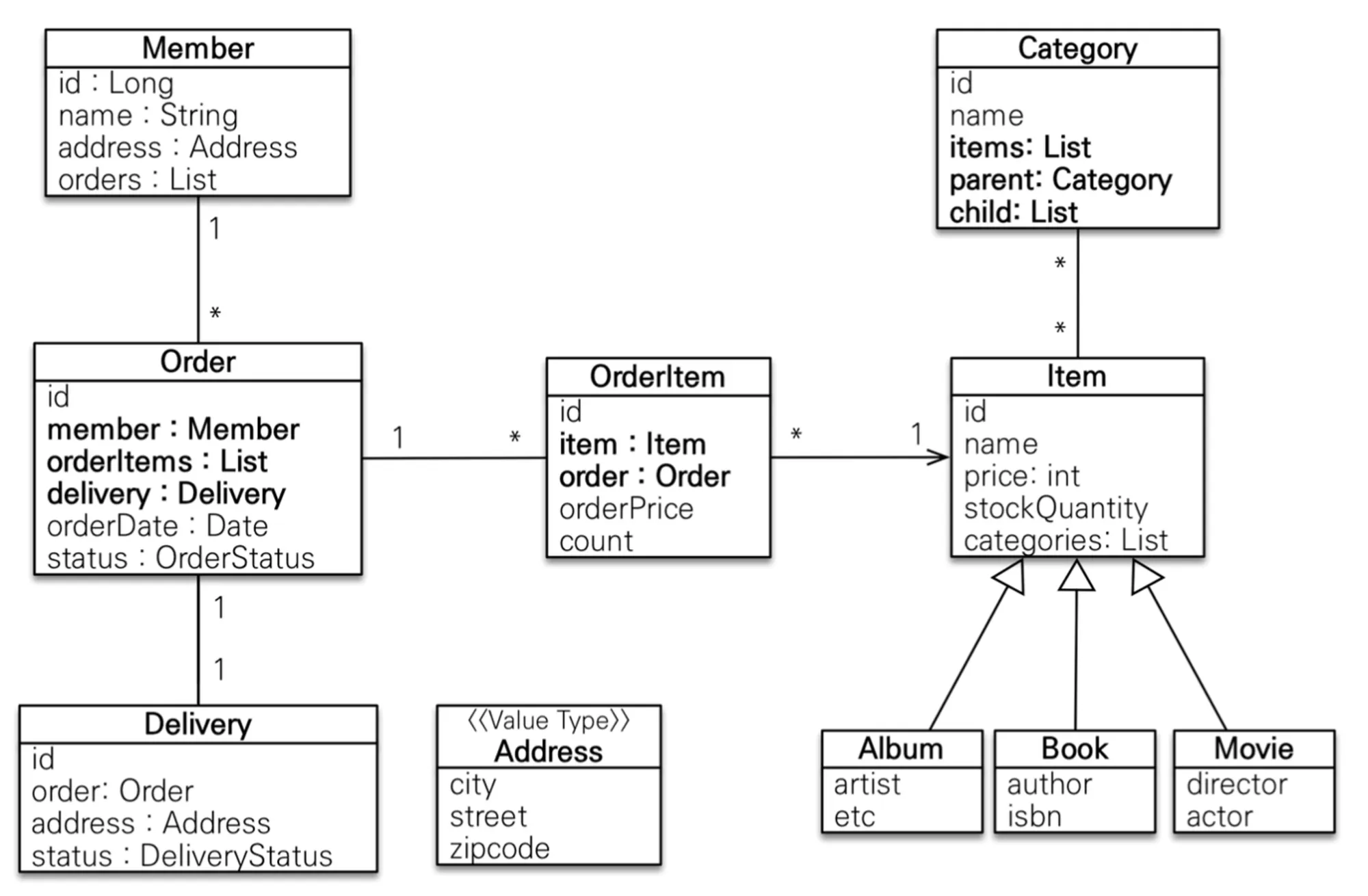
강의 예제에서도 CASCADE를 활용하고 있다. 흐름을 생각해보자. 사용자가 주문을 하면 Order 객체가 생성이 되고 그에 파생되어 Delivery와 OrderItem 객체가 생성된다. 이처럼 Delivery 객체와 OrderItem 객체의 생명주기는 Order 객체의 생명주기에 의존적이다. 또한 위의 클래스 다이어그램에서 Delivery와 OrderItem을 살펴보면, 다른 엔티티에서 두 엔티티를 참조하지 않는 상태임을 확인할 수 있다. 이 경우에는, 아래 코드와 같이 영속성 전이(CASCADE)를 활용한다면 편리함을 얻을 수 있다.
@Entity
@Table(name = "orders")
@Getter @Setter
@NoArgsConstructor
public class Order {
@OneToMany(mappedBy = "order", cascade = CascadeType.ALL)
private List<OrderItem> orderItems = new ArrayList<>();
@OneToOne(fetch = FetchType.LAZY, cascade = CascadeType.ALL)
@JoinColumn(name = "delivery_id")
private Delivery delivery;
}
디자인 패턴
간단하게 보면, 비즈니스 로직 구현을 어디에서 하는가에 따라 아래 2가지 패턴으로 나뉘게 된다.
트랜잭션 스크립트 패턴
엔티티에 비지니스 로직이 거의 없고, 서비스 계층에서 비즈니스 로직을 처리하는 방법
트랜잭션 스크립트 패턴을 사용하면 엔티티는 단순히 데이터를 전달하는 역할을 하게 되지만 서비스 로직은 커지게 된다. 즉, 엔티티에는 비즈니스 로직이 거의 없으며 서비스 계층에 비즈니스 로직이 집중되어 있다. 일반적으로 우리에게 익숙한 방법이다. 모듈화만 잘 한다면 쉽게 개발이 가능하며 효율도 좋지만 로직이 복잡할수록 코드가 난잡해지며 코드의 중복을 막기 어렵다는 단점이 있다.
도메인 모델 패턴
대부분의 비즈니스 로직이 엔티티 안에 구성되어 있고, 서비스 계층은 엔티티에 필요한 역할을 위임
엔티티 안에 비즈니스 로직을 가지고 객체지향을 활용하는 기법으로 DDD(도메인이 비즈니스 로직의 주도권을 가지고 개발하는 방법)를 접목시킬 경우 이 방법을 사용한다고 한다. 즉, 대부분의 비즈니스 로직을 엔티티에 구현함으로써 서비스 계층은 엔티티를 호출하는 정도의 얇은 비즈니스 로직을 가지게 된다. 객체 지향 설계를 기반으로 하기 때문에 재사용성과 확장성, 유지 보수 측면에서 장점이 있지만 도메인 모델 구축에 많은 시간과 노력이 들어가고 객체들의 관계 및 데이터베이스와의 매핑 등 고려해야 하는 점이 많다.
그렇다면 둘 중 무엇을 쓰는 것이 좋을까? 정답은 없다. 각자의 패턴 모두 장단점이 있기 때문에 상황에 맞게 적절한 방법을 선택하는 것이 중요하다.
변경 감지와 병합
변경 감지와 병합(merge)는 모두 데이터를 수정할 때 사용하는 방식이다. 둘의 차이점은 무엇일까? 지금부터 살펴보자.
병합 (merge)
병합, em.merge() 메서드는 Detached(준영속) 상태의 Entity를 다시 영속화 하는데 사용한다. 여기서 준영속 엔티티란 영속성 컨텍스트가 더는 관리하지 않는 엔티티를 뜻한다. 아래 코드를 살펴보자.
public String updateItem(@ModelAttribute("form") BookForm form) {
Book book = new Book();
book.setId(form.getId());
book.setName(form.getName());
book.setPrice(form.getPrice());
book.setStockQuantity(form.getStockQuantity());
book.setAuthor(form.getAuthor());
book.setIsbn(form.getIsbn());
itemService.saveItem(book);
return "redirect:/items";
}
위의 코드에서 Book 객체는 준영속 상태이다. setId() 메서드에서 확인할 수 있듯 Book 객체는 DB에 한번 저장되어 식별자가 존재하는 객체이다. 하지만 우리는 new 연산자를 통해 새로운 객체를 생성하였기 때문에 현재 book 객체는 영속성 컨텍스트가 관리하지 않는다. 즉, 정리하면 준영속 엔티티의 핵심은 ‘**식별자를 기준으로 영속상태가 되어 DB에 저장된적이 있는가’**이다. 이러한 준영속 엔티티는 JPA가 관리를 하지 않기 때문에 객체를 수정을 해도 DB에 Update가 일어나지 않는다.
@Transactional
void update(Item itemParam) { // itemParam : 파리미터로 넘어온 준영속 상태의 엔티티
Item mergeItem = em.merge(itemParam);
// itemParam은 여전히 준영속, mergeItem은 영속 상태가 된다.
}
이러한 준영속 엔티티를 수정하기 위한 방법 중 하나로 병합이 존재한다. em.merge() 메서드를 호출함으로써 준영속 상태의 엔티티를 영속 상태로 변경한 후 데이터를 수정하는 것이다.

먼저 merge()가 실행되면 파라미터로 넘어온 준영속 엔티티의 식별자 값으로 1차 캐시에서 엔티티를 조회한다. 이때, 1차 캐시에 엔티티가 존재하지 않으면 DB에서 엔티티를 조회하고 1차 캐시에 저장한다. 이렇게 조회한 영속 엔티티의 값을 member 엔티티(준영속 상태였던 엔티티)의 값들로 모두 교체한다. HTTP 메서드 중 PUT과 비슷하게 동작한다고 생각하면 된다. 그 후 트랜잭션 커밋 시점에 변경 감지 기능이 동작하여 DB에 update 쿼리가 실행된다.
정리하면 merge() 메서드는 준영속 엔티티를 그대로 영속 상태로 변경하지 않고, 해당 엔티티의 데이터를 기반으로 새로운 영속 엔티티를 반환한다. 즉, 원래의 준영속 엔티티는 여전히 준영속 상태로 남아 있고, merge() 메서드로 반환되는 엔티티만 영속 상태가 된다. 때문에 merge()메서드로 반환된 엔티티와 기존의 준영속 엔티티와의 동일성이 보장되지 않는다는 문제가 있다. 더하여 이러한 병합 방식은 원하는 속성만 선택해서 변경할 수 없다. 즉, 모든 필드들이 통째로 교체되기 때문에 병합 시 값이 존재하지 않는다면 null 값으로 업데이트 되는 위험이 존재한다. 아까의 예시 코드에서 만약 book.setAuthor(form.getAuthor()); 를 작성하지 않았다면 Author 속성이 null값으로 변경되어 DB에 저장된다는 뜻이다. 그렇기 때문에 병합보다는 변경 감지를 이용하여 데이터를 수정하는 것을 권장한다.
변경 감지 (dirty checking)
앤티티를 변경할 때 가장 좋은 방법은 변경 감지를 사용하는 것이다.
@Transactional
public void updateItem(Long id, String name, int price, int stockQuantity) {
Item item = itemRepository.findOne(id);
item.setName(name);
item.setPrice(price);
item.setStockQuantity(stockQuantity);
}
위의 코드처럼 findOne() 메서드를 통해 Item 객체를 영속화한 후, 데이터를 수정하면 트랜잭션 커밋 시점에 변경 감지가 실행되어 자동으로 update 쿼리가 실행된다.
'JPA&JDBC' 카테고리의 다른 글
| [JPA] 실전! 스프링 부트와 JPA 활용 2 - 섹션 5~6 (0) | 2025.03.17 |
|---|---|
| [JPA] 실전! 스프링 부트와 JPA 활용 2 - 섹션 1~4 (0) | 2025.03.17 |
| [JPA] 실전! 스프링 부트와 JPA 활용1 - 섹션 1~2 (0) | 2025.03.17 |
| [JPA] 자바 ORM 표준 JPA 프로그래밍 - 섹션 10~11 (0) | 2025.03.17 |
| [JPA] 자바 ORM 표준 JPA 프로그래밍 - 섹션 8~9 (0) | 2025.03.17 |