HTTP 1
HTTP/0.9는 오직 GET 메서드만 지원했으며, 요청에 헤더가 존재하지 않았다. 응답 역시 상태 코드나 헤더 없이 오직 HTML 파일의 본문만 포함되어 있었다.
HTTP/1.0에서는 비로소 상태 코드와 헤더가 도입되었고, POST 등의 추가적인 메서드들도 지원되기 시작했다. HTTP는 처음에 하나의 요청(request)에 대해 하나의 응답(response)만을 주고받는 단순한 구조로 시작했다.
즉,
1. 서버와 TCP 연결을 맺고(3-way handshaking)
2.요청을 보내고
3.응답을 받은 후
4. TCP 연결을 닫는다.
HTTP 1.0은 매 요청마다 이런 4 단계를 반복하는 구조였다. 하지만 이런 방식은 매 요청마다 새로운 TCP 연결을 생성해야 한다는 점, 웹이 점점 더 미디어 중심으로 변하면서, 매번 응답 후에 연결을 끊는 것은 비효율적이라는 한계에 직면했다. 이러한 한계를 해결하기 위해 등장한 것이 HTTP/1.1이다
HTTP/1.1 의 특징
Persistent Connections
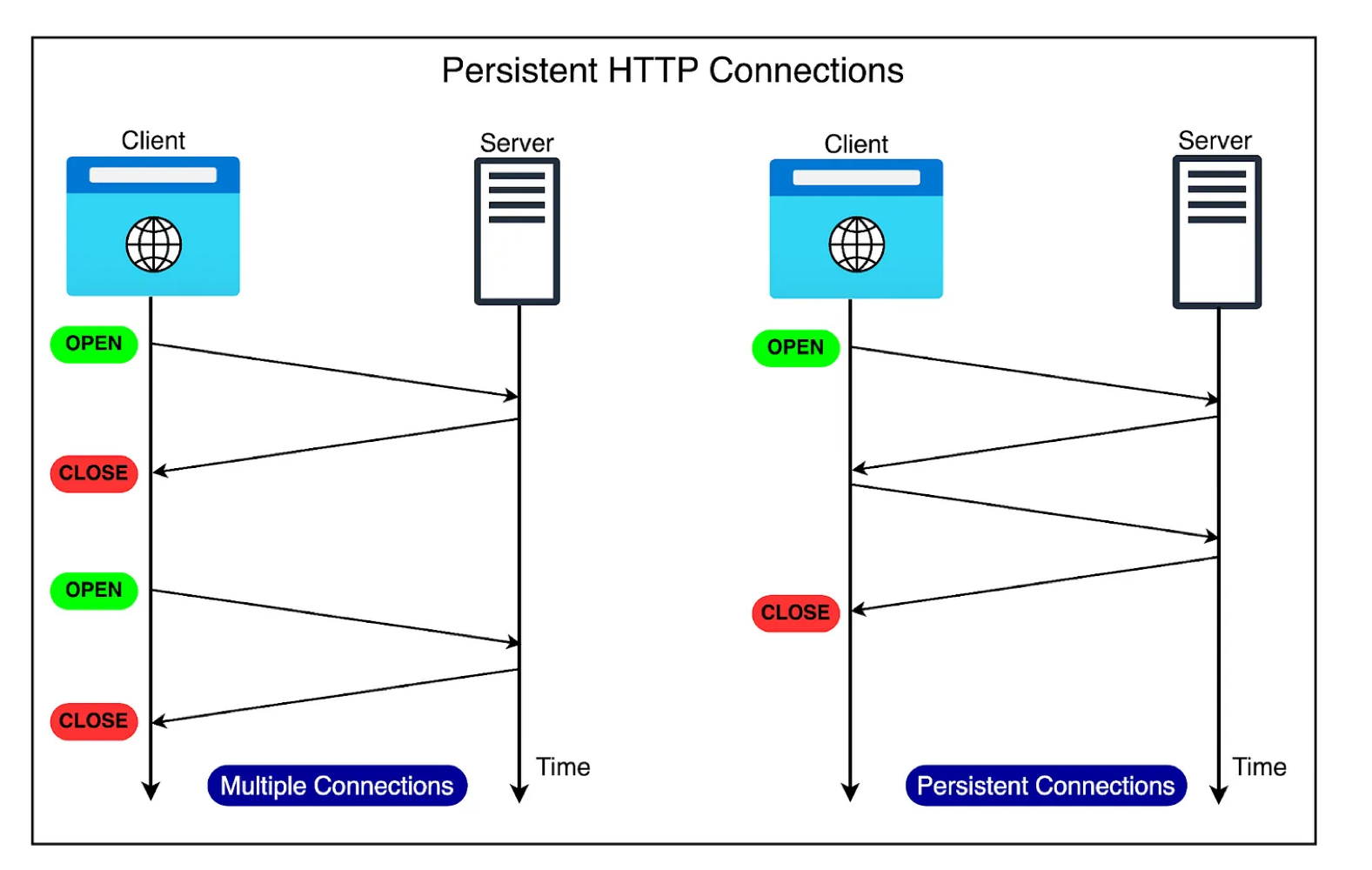
HTTP/1.1은 지속 연결(persistent connections)을 지원함으로써 이러한 오버헤드를 제거했다. TCP 연결을 닫으라는 특별한 요구가 없는 한 연결은 계속 유지된다. 그 결과, HTTP/1.1에서는 요청마다 연결을 끊을 필요가 없고, TCP 핸드셰이크도 여러 번 수행할 필요가 없게 되었다
Pipelining

HTTP/1.1에서는 Pipelining이라는 개념도 도입했다. Pipelining이란, 클라이언트가 하나의 TCP 연결을 통해 여러 요청을 각각의 응답을 기다리지 않고 연속해서 보낼 수 있도록 하는 것을 말한다. 쉽게 말해, 하나의 커넥션에서 요청에 대한 응답을 기다리지 않고 순차적인 여러 요청을 연속적으로 보내서 그 순서에 맞춰 응답을 받는 방식이다. 각 요청에 대한 응답을 기다리지 않고 다음 요청을 보낼 수 있도록 하여 지연(Latency)을 줄임으로써 성능을 향상시켰다. 하지만 Pipelining에도 head-of-line blocking(HOL)라는 한계가 존재한다.
Chunked Transfer Encoding
청크 전송 인코딩(Chunked Transfer Encoding) 방식은 HTTP 1.1에서 도입된 스트리밍 데이터 전송 방식으로, 데이터를 여러 개의 청크(Chunk) 단위로 나누어 순차적으로 전송하는 방법이다. 각 청크는 독립적으로 송신 및 수신이 가능하며, 전체 데이터를 한 번에 모두 준비할 필요 없이 일부 데이터가 준비되는 대로 바로 전송할 수 있다.
이 방식은 특히 대용량 데이터를 다룰 때 유용하다. 서버는 전체 데이터를 모두 처리하여 한 번에 보내는 대신, 준비된 부분부터 청크 단위로 나누어 클라이언트에 순차적으로 전달할 수 있다. 때문에 클라이언트는 데이터를 더 빠르게 수신을 시작할 수 있으며, 서버는 데이터 생성이나 추가 작업을 계속하면서 동시에 청크를 전송할 수 있다. 비유하자면, 택배를 보낼 때 모든 상품이 준비될 때까지 기다린 후 한 번에 보내는 대신, 준비되는 대로 박스를 하나씩 따로따로 먼저 보내는 것과 같다. 청크 전송은 데이터가 모두 전송된 후에 별도의 응답을 보내는 것이 아니라, 청크들의 연속 자체가 응답이 된다. 서버는 마지막으로 크기가 0인 청크를 보내며 데이터 전송이 완료되었음을 알린다.
이처럼 청크 전송 방식을 사용하면 전체 작업이 완료될 때까지 기다릴 필요가 없어 전송이 더욱 빠르고 효율적이다.
Caching and Conditional Requests
HTTP/1.1에서는 웹 성능을 더 높이기 위해 캐시를 보다 정교하게 관리하는 방법이 추가됐다.
대표적으로 Cache-Control이나 ETag 같은 헤더를 도입했는데, 이러한 헤더들 덕분에 클라이언트(브라우저)와 서버가 서로 불필요한 데이터 전송을 줄이고 저장된 데이터를 더 효과적으로 관리할 수 있게 되었다. 또한, If-Modified-Since나 If-None-Match 같은 조건부 요청도 사용할 수 있게 되었다. 이런 조건부 요청은 리소스가 변경된 경우에만 서버로부터 새 데이터를 받아오게끔 하기 때문에, 데이터 트래픽을 줄이고 웹 성능도 개선할 수 있다. 즉, 필요할 때만 데이터를 갱신하는 거니까, 서버도 덜 바쁘고, 사용자도 더 빠른 웹을 경험할 수 있게 된 것이다.
HTTP/1.1 의 한계
웹사이트는 점점 더 커졌고, 다운로드해야 할 리소스도 많아졌으며, 네트워크를 통해 전송되는 데이터의 양도 늘어났다. 이러한 웹의 성장 속도는 HTTP/1.1의 근본적인 성능 문제를 드러내게 되었다.

위 사진을 흐름을 파악해보자. 브라우저가 먼저 HTML 파일을 받은 뒤, 첫 번째 이미지를 요청한다. 이 요청에는 100ms의 지연이 발생한다. 이후 두 번째 이미지 요청이 이어지고, 다시 100ms의 지연이 발생한다. 결국 모든 리소스를 순차적으로 요청하고 받아와야 하므로, 브라우저는 모든 파일을 다 받아야만 페이지 렌더링을 완료할 수 있다. 이처럼 웹페이지에 포함된 리소스(이미지, 스크립트 등)가 많아질수록 왕복 지연 시간(RTT)이 누적되어 전체 페이지 로딩 속도가 느려지는 문제가 발생한다.
Pipelining -> Head-Of-Line Blocking (HOL)
이 문제를 완화하기 위해 HTTP/1.1에서는 몇 가지 우회적인 방법들이 도입되었는데, 그 중 하나가 Pipelining이다. 하지만, 앞서 언급했듯 Pipelining에도 head-of-line blocking(HOL)라는 한계가 존재한다.
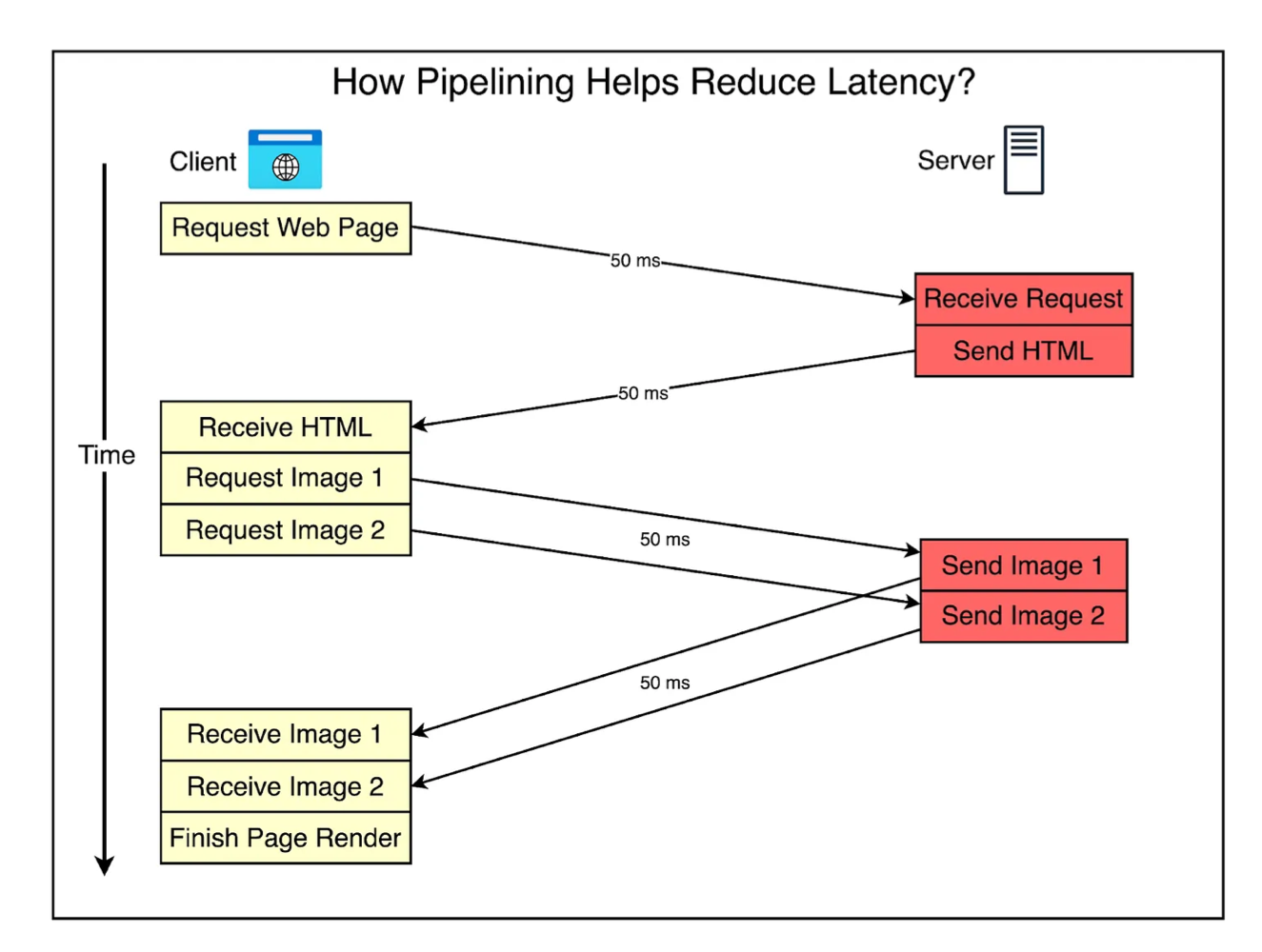
파이프라이닝을 사용하면, 클라이언트가 첫 번째 이미지 요청에 대한 응답을 기다리지 않고 바로 두 번째 이미지 요청을 이어서 보낼 수 있다. 덕분에 아까의 요청 흐름과 비교했을 때, 전체 요청 과정에서 약 100밀리초를 절약할 수 있다. 하지만, 응답을 처리하는 방식은 여전히 큐(Queue)처럼 동작하기 때문에 맨 앞에 있는 요청이 지연되면, 뒤따르는 모든 요청까지 함께 지연되는 현상이 발생한다. 이러한 문제를 head-of-line blocking(HOL)이라고 한다.
Use Multiple HTTP Connections
HTTP/1.1의 Head-of-Line Blocking문제는 하나의 도메인 당 여러 개의 HTTP 연결을 지원함으로써 어느정도 해결되었다. (대부분의 인기 브라우저는 도메인 당 최대 6개의 연결을 지원한다.)
여러 개의 서브도메인을 생성하면 도메인마다 새로운 6개의 연결을 추가로 확보할 수 있어 정적 파일들을 병렬적으로 처리할 수 있다. 즉, 하나의 연결만 사용하면 요청들이 순차적으로 처리되기 때문에 HOL 문제가 발생하지만, 여러 연결을 사용하면, 각각의 연결이 독립적으로 병렬 처리되기 때문에, 하나의 연결에서 병목이 발생하더라도 다른 연결에 영향 없이 동작할 수 있는 것이다. 이러한 기법을 도메인 샤딩(Domain Sharding) 이라고 부른다.
하지만, 도메인 샤딩에도 단점이 존재한다. 여러 개의 HTTP 연결을 사용하기 위해서는, 각각의 TCP 연결을 새로 시작해야 하며, 이 과정에서 3-way handshake로 인한 연결 비용이 발생한다. 또한, 다수의 연결을 유지하기 위해 추가적인 메모리와 처리 자원(CPU) 도 필요하다. 특히, TCP는 혼잡 제어를 위해 slow-start 알고리즘을 사용하는데, 해당 알고리즘은 연결 초기에는 데이터 전송 속도가 느리게 시작되기 때문에 모든 데이터를 한 번에 주고받는 데 시간이 더 걸릴 수 있다.
Slow-Start Algorithm이란?
네트워크 혼잡을 방지하기 위한 혼잡 제어 알고리즘이다. 작동 방식은 다음과 같다.
1. 송신자는 처음에 소량의 패킷만 보낸다.
2. 수신자로부터 성공적으로 응답(ACK)을 받을 때마다, 다음 라운드에서는 전송하는 패킷 수를 점점 늘려간다.(지수적으로 증가)
3. 이 증가는 혼잡 윈도우(congestion window) 라는 한계에 도달할 때까지 계속된다.
만약 패킷 손실이 없고 응답이 지연되지 않으면, 송신자는 네트워크가 현재의 데이터량을 감당할 수 있다고 판단한다.
하지만, 패킷 손실이 발생하거나 응답이 느려지면, 네트워크에 혼잡이 발생했다고 간주하고 전송량을 줄인다.
Make Fewer Requests
HTTP/1.1의 성능 문제를 해결하기 위한 또 다른 방법은 브라우저 캐시를 활용하거나 Bundling을 통해 서버에 보내는 요청 자체를 줄이는 것이다. 예를 들어, 이미지는 스프라이팅(spriting) 기법을 사용해 여러 개의 아이콘을 하나의 큰 이미지 파일로 묶어 제공함으로써, 개별 요청을 줄이고 서버 요청 횟수를 최소화할 수 있다. 이미지 스프라이트는 이렇게 여러 개의 이미지들을 하나의 파일로 보내고 CSS를 이용해 큰 이미지에서 필요한 부분만 잘라 사용하는 방식이다.
CSS와 JavaScript의 경우에는, 여러 파일을 하나로 병합(concatenate)하고, 공백, 주석, 불필요한 문자 등을 최소화하여 파일 크기와 요청 수를 동시에 줄이는 방식이 쓰인다.
하지만 이 방식들도 단점이 있다. 이미지 스프라이트는 구현과 유지보수가 번거롭고, CSS도 그에 맞게 별도로 수정해야 하므로 개발자에게 부담이 될 수 있다. 또한 모든 웹사이트가 빌드 도구를 활용해 JS/CSS 파일을 압축하거나 병합하는 작업을 자동화하고 있는 것은 아니기 때문에, 항상 적용되는 방법은 아니라는 한계도 존재한다.
HTTP 2
2015년, HTTP 1의 한계들을 극복하기 위해 HTTP 2가 탄생했다.
HTTP 2의 주요 특징
Binary Framing Layer
HTTP/1은 사람이 읽을 수 있는 평문(plain-text) 형식으로 메시지를 전송한다. 하지만 이 방식은 컴퓨터가 메시지를 파싱하고 해석하는 데 시간이 오래 걸리는 단점이 존재했다.
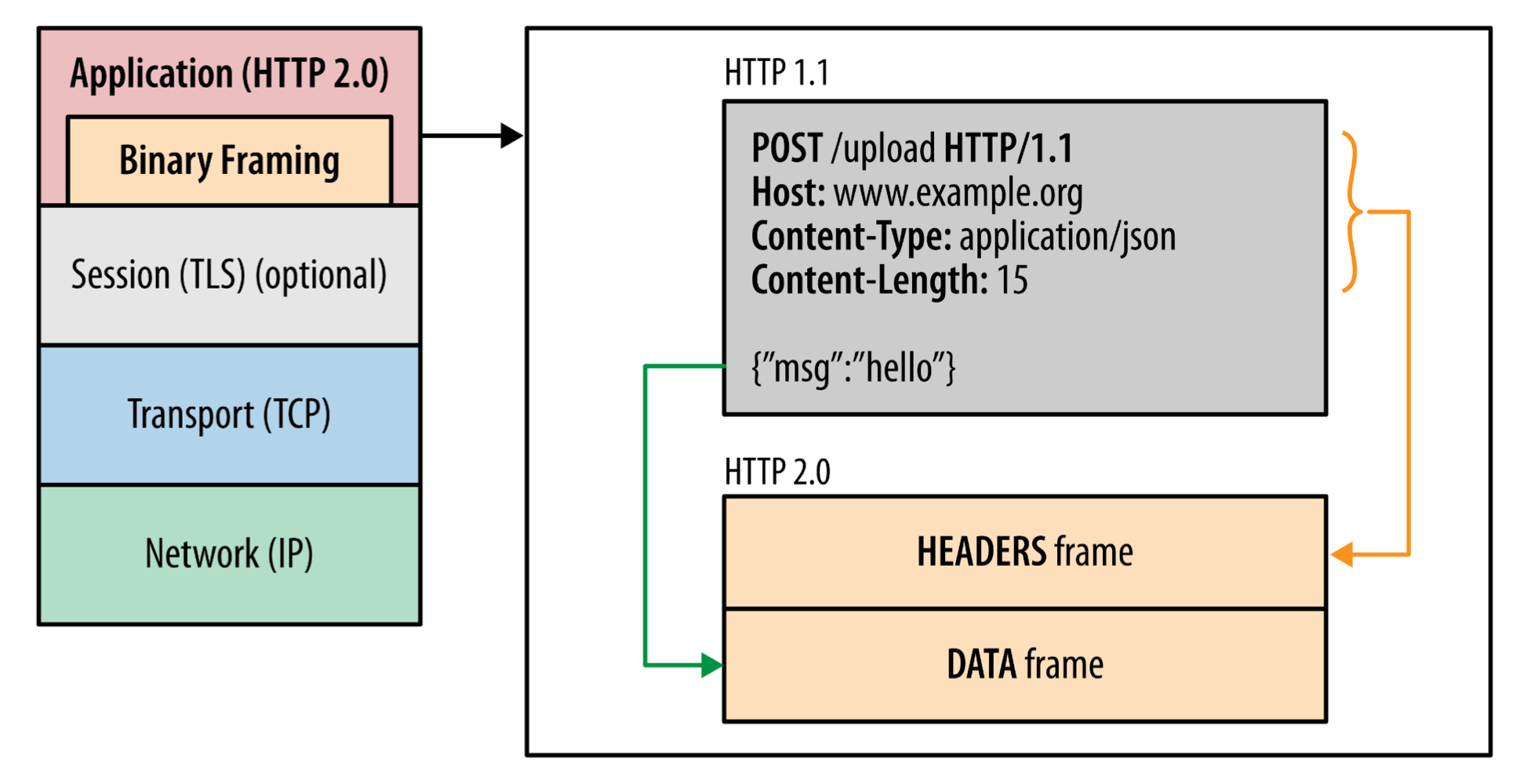
HTTP 2에서는 애플리케이션 계층과 전송 계층 사이에 바이너리 포맷 계층을 추가하여 HTTP 메시지를 바이너리 형식으로 바꾸고, 이를 프레임 단위로 쪼개어 동시에 여러 요청을 병렬로 처리할 수 있게 되었다. 바이너리 형식을 사용함으로써 효율성 뿐만 아니라 공백, 대소문자, 줄바꿈 처리 등에 여러 "helpers"가 필요했던 HTTP/1에 비해 오류 가능성이 낮아졌다.
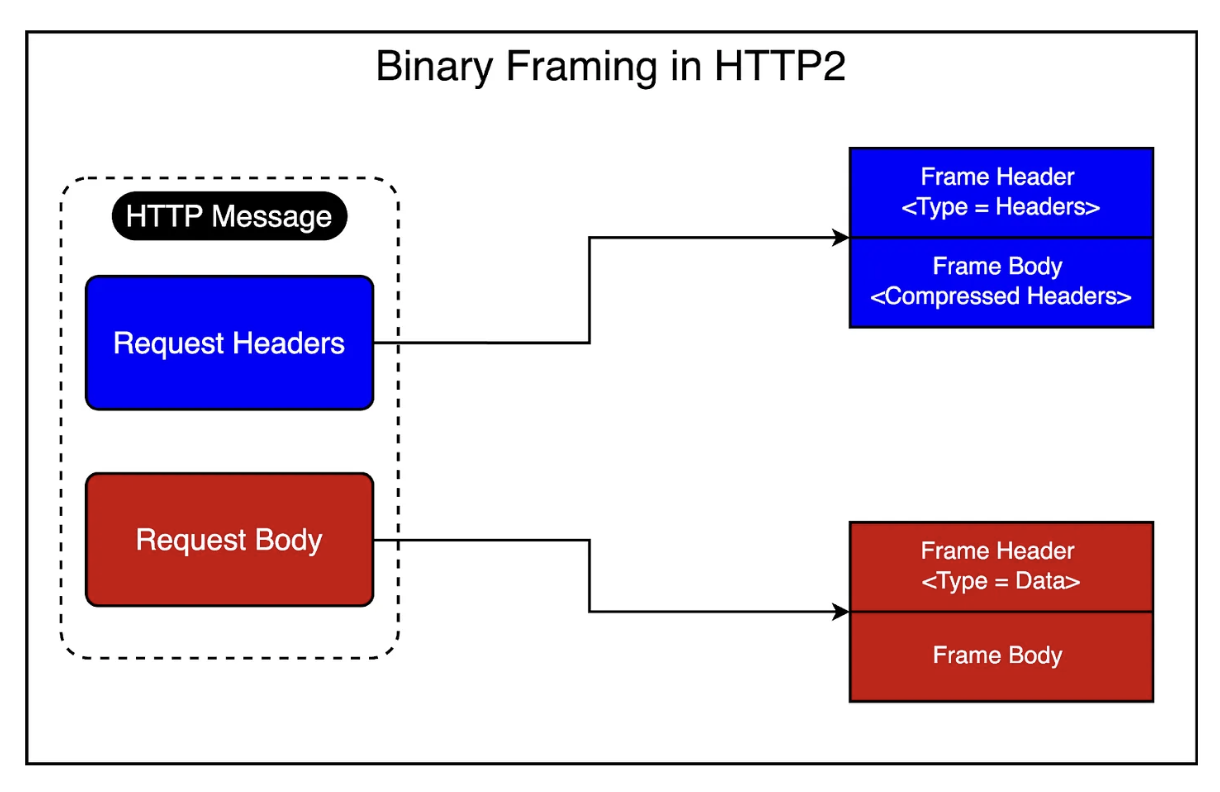
HTTP/2는 HTTP 요청의 데이터와 헤더 섹션을 서로 다른 프레임으로 분리한다. Header 프레임은 콘텐츠 유형, 인코딩 방식, 캐시 지시어 등의 요청 또는 응답에 대한 메타데이터를 담고 있고 Data 프레임은 실제 페이로드나 메시지 내용을 포함하고 있다.
이러한 구조 덕분에, HTTP/2는 동시에 여러 요청과 응답을 처리할 수 있는 멀티플렉싱이 가능하다. 서로 다른 스트림의 프레임들이 하나의 TCP 연결 위에서 병렬로 전송될 수 있기 때문이다. 또한 가장 좋은 점은 HTTP/2가 기존 HTTP/1.1과 동일한 HTTP 의미 체계를 유지한다는 것이다. 즉, 기존의 GET, POST 같은 HTTP 메서드 그리고 각종 헤더 필드 등 그대로 유지된다. 덕분에 기존 웹 애플리케이션도 HTTP/2 환경에서 별다른 수정 없이 정상적으로 작동할 수 있다.
Multiplexing
HTTP/2가 HTTP/1과 가장 크게 다른 점 중 하나는, 하나의 TCP 연결 안에서 여러 개의 요청과 응답을 동시에 처리할 수 있다(Multiplexing)는 점이다. 그리고 이것이 가능한 이유가 바로 앞서 설명한 Binary Framing Layer라는 핵심 기술 덕분이다.

HTTP/1에서는 여러 요청을 병렬로 보내기 위해 여러 개의 TCP 연결을 사용해야 했다. 하지만 HTTP/2.0에서는 단 하나의 TCP 연결만으로도 여러 요청들을 동시에 처리할 수 있다. 이는 HTTP/2가 요청과 응답 메시지를 작은 단위의 프레임(frame) 단위로 나누고, 각 프레임을 스트림(stream)이라는 개별 채널을 통해 전송하기 때문이다. 각 프레임에는 고유한 스트림 ID와 프레임 길이 등의 정보가 포함되어 있어, 전송 도중 프레임들의 순서가 뒤섞이더라도 수신 측에서는 이를 정확하게 구분하고 원래 순서대로 재조립 할 수 있다.
Stream Prioritization
HTTP/1에서는 요청과 응답이 1:1 순차적으로 처리되었기 때문에 프로토콜 차원에서 우선순위 개념이 필요하지 않았고, 클라이언트가 전송 순서를 제어했다. 하지만 HTTP/2에서는 서버가 여러 리소스를 동시에 전송할 수 있기 때문에, 어떤 리소스를 먼저 보낼지 정하지 않으면 비효율적인 순서로 전송될 수 있다. 이를 해결하기 위해서 HTTP/2에서는 각 스트림마다 우선순위를 설정하여 서버에서 더 높은 우선순위를 가진 요청에 대해 프레임을 더 많이 할당하여 먼저 처리할 수 있도록 지원한다.
Server Push
HTTP/2.0에서는 'Server Push'라는 기능도 지원한다.

Server push는 말 그대로 서버가 리소스를 클라이언트에 push할 수 있다는 것이다. 예를 들어서, 위 사진처럼 클라이언트가 HTML 페이지를 요청할 때 서버가 그와 함께 css 파일과 같은 추가적인 리소스도 함께 전송할 수 있다. 이는 마치 클라이언트가 명시적으로 요청하기도 전에, 서버가 미리 리소스를 제공해주는 것과 같기 때문에 'Server Push'라고 하며 클라이언트 입장에서는 서버가 보내는 리소스를 받아서 캐시에 저장할 수도 있고, 원하지 않는다면 거절할 수도 있다.
Compression
HTTP/1.1에서는 본문(payload)만 압축되고, 데이터에 대한 정보를 담고 있는 헤더는 plain text로 전송된다. 그러나 API 호출이 많은 웹 애플리케이션이 증가하면서, 수많은 요청을 주고받는 과정에서 헤더의 양도 함께 증가하면서 성능에 영향이 미치기 시작했다.
HTTP/2는 이 문제를 해결하기 위해 HPACK이라는 전용 압축 방식을 도입했다.

위 사진을 보면 요청1과 요청2의 대부분의 필드들이 같은 값을 가지고 있다. HTTP/2는 HPACK을 이용해, 이미 전송한 공통된 필드 값들은 인덱스로 참조하고, 달라진 path 필드만 새로 인코딩해서 전송함으로써 전체 헤더 크기를 줄인다.
HTTP 3
웹이 계속 발전하고 웹 애플리케이션이 점점 더 복잡해지면서, TCP의 한계점이 점점 더 뚜렷하게 드러나기 시작했다. 멀티플렉싱과 헤더 압축 같은 중요한 개선 사항들을 도입했음에도, 연결 지향 통신 프로토콜인 TCP의 특성 때문에 성능과 지연(latency) 측면에서 여전히 문제가 발생했다. 이러한 한계를 해결하기 위해 대체 전송 프로토콜을 탐색하기 시작했고, 그 결과 등장한 것이 바로 QUIC(Quick UDP Internet Connections)이다.
QUIC(Quick UDP Internet Connections)

QUIC은 구글에서 설계된 범용 목적의 전송 계층 통신 프로토콜로, TCP의 성능을 개선하고자 UDP기반으로 만들어진 프로토콜이다. UDP는 처리 속도가 빠른 반면 데이터의 신뢰성 확보가 어렵지만, QUIC 계층을 추가하여 TCP만큼 신뢰성을 제공할 수 있게 하였다.
QUIC의 장점
- 지연 시간 감소
QUIC은 연결을 맺을 때 Zero Round Trip Connection 방식을 사용하여 초기 페이지 로딩 속도와 반응성을 크게 향상시킨다.
또한, QUIC은 Connection UUID라는 고유한 패킷 식별자를 사용하므로 한번이라도 클라이언트와 서버가 데이터 전송을 수행했다면, 클라이언트가 요청을 보내면 서버는 추가 handshake 없이 바로 처리할 수 있어 지연 시간(latency)을 크게 줄일 수 있다. - 멀티플렉싱
HTTP/2와 유사하게, 하나의 연결로 여러 요청을 동시에 처리할 수 있으며, 때문에 HOL 문제도 해결된다. - 보안 강화
QUIC은 기본적으로 암호화를 지원하므로, 클라이언트와 서버 간의 모든 데이터가 더 안전하게 보호된다.
HTTP/3는 TCP 대신 QUIC을 기반으로 하여, 기존 HTTP/2에서 발생하던 전송 계층의 한계를 해결하고자 했다.
HTTP/3 동작 과정
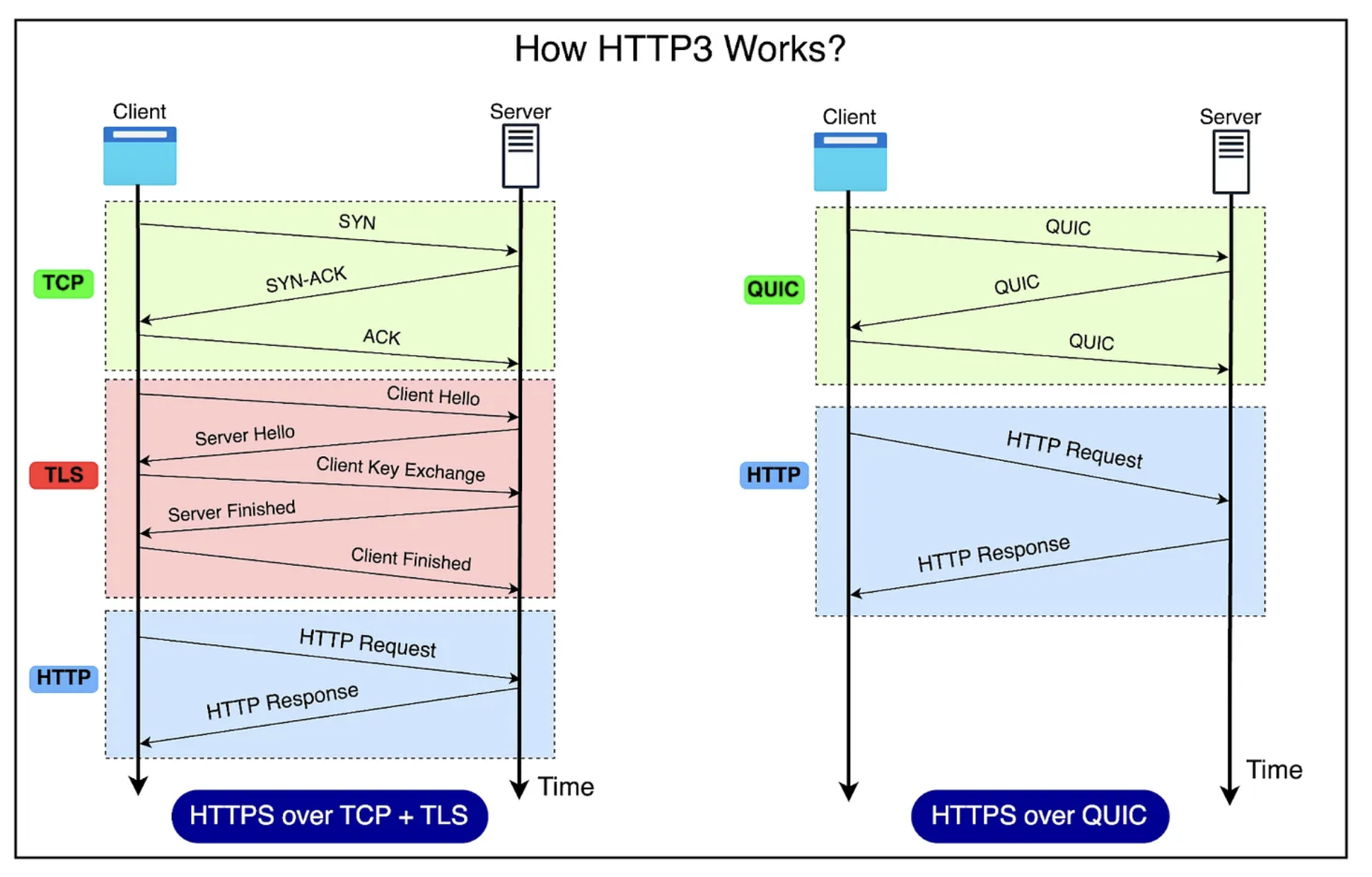
1. 클라이언트가 HTTP/3를 통해 서버에 연결하고자 할 때, QUIC handshake 과정을 통해, 연결을 설정한다. 이때, QUIC는 TLS 1.3과 통합되어 암호화 및 보안을 제공한다. TLS handshake는 QUIC 연결 설정과 동시에 수행되므로, 전체적인 지연 시간을 줄일 수 있다.
2. 클라이언트-서버 연결이 완료되면, 클라이언트는 서버로 HTTP 요청을 보낸다. 요청은 작은 데이터 패킷으로 분할되어 QUIC을 통해 UDP 기반으로 전송된다.
3. 서버가 요청을 처리하면, 응답을 다시 작은 패킷들로 나누어 클라이언트에게 전송한다.
4. 요청과 응답을 모두 마친 후, 클라이언트나 서버는 QUIC을 통해 연결을 종료한다.
가장 최신 버전인 HTTP/3는 아직 초기 채택 단계에 있지만, 2022년 표준화 이후 점점 주목을 받고 있으며 Google과 Cloudflare와 같은 주요 기술 기업들이 HTTP/3의 구현과 보급에 앞장서고 있다.
정리

참고 자료
https://blog.bytebytego.com/p/http1-vs-http2-vs-http3-a-deep-dive
HTTP1 vs HTTP2 vs HTTP3 - A Deep Dive
What has powered the incredible growth of the World Wide Web? There are several factors, but HTTP or Hypertext Transfer Protocol has played a fundamental role. Once upon a time, the name may have sounded like a perfect choice. After all, the initial goal o
blog.bytebytego.com
https://bentist.tistory.com/36
HTTP/1.1, HTTP/2, QUIC 차이 (TCP, UDP 개념 포함)
HTTP 버전별 차이를 설명하기 이전에 위 그림의 통신 모델에서 Transport(전송) 계층의 역할부터 알아본다. 전송 계층은 목적지(서버)에 신뢰할 수 있는 데이터를 전송하기 위해 필요하다. 물론 물리
bentist.tistory.com
'네트워크' 카테고리의 다른 글
| 트러블슈팅 - 로드밸런서의 동작 원리 (feat. Redis Pub/Sub) (0) | 2025.08.23 |
|---|---|
| TLS 1.2 vs TLS 1.3 (0) | 2025.05.16 |